MongoDB vs PostgreSQL - A Technical Comparison
As a backend developer, you’ve probably faced that moment in a project when you have to make a critical decision, which database should you choose?
You’ve got your architecture mapped out, your APIs planned, and your team is ready to ship but then comes the question of data storage. Do you go with something flexible and schema-less, or do you opt for the tried-and-true relational model? It’s a decision that can make or break the scalability, performance, and even the success of your application. MongoDB and PostgreSQL are two heavyweights in the open-source database world.
- MongoDB offers the freedom of a NoSQL document-based structure, perfect for rapidly evolving applications.
- PostgreSQL, on the other hand, gives you the rock-solid reliability of a relational database with advanced querying capabilities. Both have their unique strengths, and as a backend developer, knowing which one to pick for your project is crucial.
In this article, I'll dive deep into the technical differences between MongoDB and PostgreSQL, providing the insights you need to make the right choice.
What Is PostgreSQL?
PostgreSQL is a relational database management system (RDBMS) that has been around since the 1980s, with roots in the POSTGRES project at the University of California, Berkeley. If you’re looking for stability, consistency, and a powerful query language, PostgreSQL is hard to beat. Over the past 30 years, it has evolved into a highly reliable, open-source database used by everyone from startups to Fortune 500 companies.
PostgreSQL is known for its strong adherence to SQL standards, but it doesn’t stop there. It extends SQL with additional features like custom data types, functions, and even support for object-oriented concepts.
It’s ACID-compliant, meaning it ensures the reliability of transactions which is a big deal when you’re working on financial applications, ecommerce platforms, or any system that requires data integrity. It’s features like Multi-Version Concurrency Control (MVCC) and a powerful query optimizer, PostgreSQL handles complex queries and high-concurrency environments with ease.
What Is MongoDB?
MongoDB, on the other hand, is the cool, relatively new kid on the block, although it’s been around since 2009. Created by developers at 10gen (now MongoDB, Inc.), MongoDB was designed to break free from the rigid structures of traditional relational databases.
It was built to solve modern apps problems, where data does not always fit neatly into tables, rows, and columns. Instead, MongoDB stores data as flexible, schema-less documents using JSON-like structures called BSON (Binary JSON).
MongoDB’s strength lies in its ability to scale horizontally. It was designed with cloud-based and distributed architectures in mind, making it ideal for apps that need to handle massive amounts of unstructured or semi-structured data, like real-time analytics platforms, content management systems, and IoT applications. The flexibility of MongoDB allows developers to evolve their data models as the application grows, without the headaches of schema migrations. With features like replica sets for high availability, sharding for scalability, and its own rich query language (MQL), MongoDB gives backend developers the freedom to build modern, distributed applications without worrying about the limitations of traditional databases.
If agility, scalability, and cloud-native development are your priorities, MongoDB is likely the tool you’re looking for
1- Data model and structure
Document- oriented mode
MongoDB takes a radically different approach to data storage compared to traditional relational databases.
Instead of enforcing rigid schemas with predefined fields, it embraces flexibility with its document-oriented model. MongoDB stores data as BSON (Binary JSON), which allows for key-value pairs where each key can have a wide range of values, including arrays and even deeply nested documents.
This schema-less approach makes MongoDB perfect for scenarios where the structure of your data is unpredictable, rapidly evolving, or non-uniform across different records.
Think about building an app where user profiles vary greatly, some users might have a list of past orders, others might not, and new fields could be added to the user profile as the application evolves.
- In MongoDB, you don’t need to worry about schema migrations or altering table structures every time you want to introduce a new field.
- Documents are self-describing, and any new data can simply be added on the fly.
Here’s an example of how user data might look in MongoDB:
{ "name": "John Doe", "email": "john.doe@example.com", "orders": [ { "order_id": "001", "items": ["Book", "Pen"], "total": 25.5 } ] }
This flexibility is a huge advantage for agile development environments where iterations happen quickly, and the data model is likely to change over time.
MongoDB’s ability to accommodate unstructured or semi-structured data without requiring schema migrations is a game-changer for many developers. You can add fields, nest documents, and even remove them without worrying about breaking the database. For example, if later on, you need to add a "phone number" field to some users, you simply add it to those documents, and MongoDB handles it without issue. There’s no downtime or need to restructure the database. This makes MongoDB a favorite for developers working in fast-paced environments where flexibility is key.
PostgreSQL: Relational model
On the flip side, PostgreSQL sticks to the more traditional relational model, which brings its own advantages.
Data in PostgreSQL is organized into tables composed of rows and columns, where each row must conform to a predefined schema. This means that before inserting any data, you need to define the structure of your tables and enforce data types for each column. It’s a more rigid approach, but this rigidity translates into reliability, consistency, and integrity.
Here’s the same user data modeled in PostgreSQL:
CREATE TABLE users ( id SERIAL PRIMARY KEY, name VARCHAR(100), email VARCHAR(100) ); CREATE TABLE orders ( id SERIAL PRIMARY KEY, user_id INT REFERENCES users(id), items TEXT[], total DECIMAL(10, 2) );
In this model, every row in the users table represents a user, and the orders table stores their corresponding orders, linked via a foreign key. If you need to add a new field, such as a phone number, you’ll need to explicitly alter the table:
ALTER TABLE users ADD COLUMN phone VARCHAR(15);
While this may seem cumbersome, it offers strong data integrity guarantees. Every record in PostgreSQL conforms to the schema, which means you can rely on consistent data types, relationships, and constraints (like foreign keys or unique indexes) across your tables. This is especially useful in scenarios where data consistency and strict validation are critical, such as financial systems or any application requiring complex transactions.
PostgreSQL’s structured approach also lends itself well to sophisticated queries, where relationships between tables are central. If you need to run complex reports, analyze data using aggregate functions, or work with transactional integrity, PostgreSQL’s rigid schema ensures your data is well-organized and relational constraints are enforced.
Its adherence to ACID properties (Atomicity, Consistency, Isolation, Durability) ensures that transactions are processed reliably, making it the go-to choice for applications with heavy reliance on data integrity.
2. Query Language and Syntax
MongoDB Query Language (MQL)
MongoDB offers its own custom query language, MQL (MongoDB Query Language), tailored to interact with its document-based storage model. MQL is designed to work directly with BSON (Binary JSON), allowing developers to query, update, and transform data efficiently within MongoDB's schema-less environment.
One of MongoDB’s core strengths lies in its simplicity and flexibility for querying unstructured or semi-structured data. Because of its document model, you can easily run queries on nested structures, without having to worry about predefined schema constraints.
For example, a simple query to find all users from the USA would look like this:
db.users.find({ country: "USA" });
That’s a straightforward query that fetches all documents where the country field is set to "USA." But what really sets MongoDB apart is its ability to dive deep into nested documents and run complex queries effortlessly. For instance, if you need to find all users whose total order value exceeds 100, you can query the nested orders array like this:
db.users.find({ "orders.total": { $gt: 100 } });
This type of query shows MongoDB’s power in handling complex, multi-level data structures. There’s no need to create complex joins like you would in a relational database; the data is all contained within the document. MQL also supports advanced operations such as projections (to limit which fields are returned), geospatial queries, and aggregation pipelines for transforming and analyzing data.
The aggregation framework in MongoDB is particularly useful for handling large datasets, allowing you to group, filter, and process documents in a pipeline-based approac.
PostgreSQL’s SQL
On the other side, PostgreSQL uses SQL (Structured Query Language), the long-established standard for interacting with relational databases.
_ SQL has been around for decades and is widely known and supported across the tech industry. _ PostgreSQL adheres to the SQL standard but also extends it with powerful features that make it stand out.
Let’s start with a simple query to retrieve all users from the USA in PostgreSQL:
SELECT * FROM users WHERE country = 'USA';
Just like MongoDB, this query is simple and intuitive. However, PostgreSQL’s power becomes evident when you start working with complex relational data. SQL excels in handling relationships between tables, often through JOIN operations. If your data is normalized and spread across multiple tables, SQL allows you to connect and query that data efficiently.
One feature that makes PostgreSQL particularly interesting is its native support for JSON, allowing it to handle semi-structured data just like MongoDB.
For instance, if you have a column that stores JSON data, you can query it using standard SQL syntax:
SELECT * FROM users WHERE data->>'country' = 'USA';
In this example, data is a JSONB column, and the arrow operator (->>) extracts the value of the country field.This feature allows PostgreSQL to bridge the gap between relational and NoSQL databases by letting developers store and query both structured and semi-structured data in the same database.
PostgreSQL also introduces advanced SQL features like Common Table Expressions (CTEs) and window functions, which can make complex queries more readable and efficient. For example, you can use CTEs to break down complex queries into simpler parts, while window functions allow you to perform calculations across sets of rows.
Here’s an example using CTEs to simplify a query:
WITH RecentOrders AS ( SELECT user_id, total FROM orders WHERE order_date > '2024-01-01' ) SELECT users.name, RecentOrders.total FROM users JOIN RecentOrders ON users.id = RecentOrders.user_id;
This query first creates a temporary result set (RecentOrders) and then uses it to perform a more readable and efficient JOIN with the users table. These types of advanced features are where SQL really shines, especially when dealing with complex datasets in enterprise environments.
3. Indexing and Query Processing
MongoDB Indexing
In MongoDB, indexing is crucial for optimizing query performance, especially when dealing with large datasets. MongoDB supports several types of indexes, including B-tree, compound, text, geospatial, and hashed indexes, which are designed to handle different types of queries.
One of MongoDB’s key advantages is its ability to index any field within a document, even deeply nested fields inside arrays or subdocuments. This is particularly useful in MongoDB’s schema-less design, where documents might have varying structures, and queries need to target specific parts of a document. For instance, creating a text index on the content, users.comments, and users.profiles fields. With the index name to InteractionsTextIndex:
db.blog.createIndex( { content: "text", "users.comments": "text", "users.profiles": "text" }, { name: "InteractionsTextIndex" } )
MongoDB’s flexibility extends to creating compound indexes, where multiple fields are indexed together to optimize more complex queries.
Beyond simple indexing, MongoDB’s aggregation framework is another powerful tool. The aggregation pipeline allows you to process and transform documents in stages, much like a series of Unix pipes. This is especially useful for batch processing, data transformations, and complex reporting. With the help of indexes, MongoDB can optimize these pipelines to execute more efficiently by reducing the number of documents processed at each stage.
For instance, if you want to aggregate total order amounts for users, MongoDB’s aggregation pipeline makes it easy:
db.orders.aggregate([ { $match: { status: "shipped" } }, { $group: { _id: "$user_id", total: { $sum: "$total" } } }, { $sort: { total: -1 } } ]);
PostgreSQL Indexing
PostgreSQL offers a highly sophisticated and flexible indexing system that is tailored to handle a wide variety of query patterns. It supports multiple index types, such as B-tree, GIN (Generalized Inverted Index), GiST (Generalized Search Tree), SP-GiST (Space-Partitioned GiST), and BRIN (Block Range INdexes). Each index type is optimized for specific use cases, making PostgreSQL an excellent choice for complex queries and specialized data types.
Creating a basic B-tree index on a column in PostgreSQL is straightforward and similar to MongoDB:
CREATE INDEX email_idx ON users (email);
This command creates a B-tree index on the email column, improving the speed of queries that search for users by their email address. B-tree is the default index type in PostgreSQL, and it works well for most range queries and equality checks.
However, PostgreSQL’s indexing capabilities go far beyond simple B-trees. For example, GIN indexes are highly efficient for full-text search and indexing complex data types such as JSON, arrays, and hstore.
If you’re working with documents stored in JSONB columns, a GIN index can dramatically speed up queries that need to search for specific fields or values inside the JSON data. Here’s how you’d create a GIN index on a JSONB column:
CREATE INDEX users_data_idx ON users USING gin (data);
This index allows PostgreSQL to efficiently search within the data JSONB column, which could contain nested data structures similar to MongoDB documents.
In addition to GIN, PostgreSQL supports GiST indexes, which are useful for geospatial data and other non-standard data types. For example, if you need to perform spatial queries, PostgreSQL’s GiST indexes can make them run faster by indexing spatial data types like points, lines, and polygons. PostgreSQL also integrates well with the PostGIS extension for advanced geospatial queries, making it a powerful option for location-based applications.
PostgreSQL’s query planner and optimizer are among the best in class, ensuring that even the most complex queries are executed as efficiently as possible. The query planner considers factors such as table size, index selectivity, and available system resources when determining the best execution strategy. It also supports parallel query execution, allowing large queries to be processed by multiple CPU cores, further improving performance.
For instance, if you need to run a query that processes a large dataset, PostgreSQL will divide the work among multiple cores and take advantage of any available indexes, significantly speeding up query processing.
SELECT user_id, SUM(total) FROM orders WHERE status = 'shipped' GROUP BY user_id ORDER BY SUM(total) DESC;
PostgreSQL will use its powerful planner to decide whether to scan indexes, perform table scans, or use other optimization techniques like partition pruning. If the status or total columns are indexed, it will leverage those indexes to reduce the amount of data scanned, improving performance.
4. Performance and Scalability
MongoDB Performance
MongoDB is built with scalability in mind, particularly for environments that need to handle large amounts of unstructured or semi-structured data. One of MongoDB’s greatest strengths lies in its ability to scale horizontally, which is achieved through sharding.
Sharding allows MongoDB to distribute data across multiple nodes or clusters, meaning it can efficiently manage high-volume read and write operations by dividing the workload among several machines. This makes MongoDB an ideal choice for applications where data grows rapidly, such as high-traffic web applications, real-time analytics, content management systems, or IoT platforms.
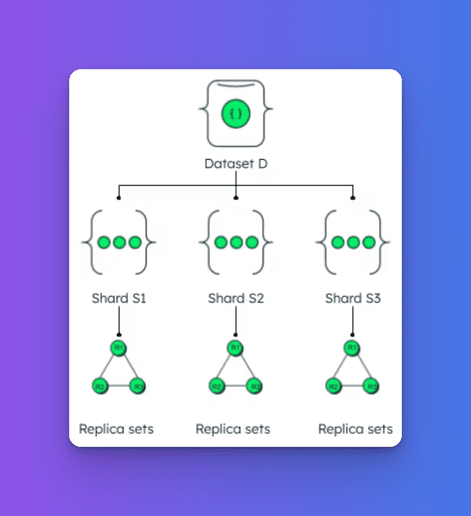
In MongoDB, sharding involves splitting the data into smaller, more manageable chunks that are distributed across different servers. These chunks are based on a shard key, which determines how the data is partitioned. Each shard holds a portion of the dataset, and MongoDB can add more shards as the system scales, ensuring high availability and fault tolerance.
MongoDB’s scalability is also enhanced by MongoDB Atlas, a fully managed cloud service that automates much of the complexity of sharding and replication. With Atlas, you can set up a distributed cluster across multiple regions and scale up or down depending on your application’s traffic, all with minimal downtime. MongoDB Atlas also handles replication automatically, ensuring that your data is continuously synchronized across regions to prevent any single point of failure.
PostgreSQL Performance
PostgreSQL, in contrast, is traditionally designed for vertical scalability, meaning that it excels at handling large datasets on a single, powerful machine. PostgreSQL is highly efficient when dealing with complex queries and large amounts of structured data, thanks to its robust query planner, indexing capabilities, and support for parallel query execution.
However, PostgreSQL also has the ability to scale horizontally through techniques such as table partitioning and replication, though it requires more effort and careful planning compared to MongoDB’s built-in sharding.
In PostgreSQL, partitioning is the process of dividing a large table into smaller, more manageable pieces called partitions. This is particularly useful for improving query performance on large datasets, as queries that filter by the partition key can target only relevant partitions, reducing the amount of data scanned. Partitioning is typically done by range, list, or hash. Here’s an example of how you might partition an orders table by total in PostgreSQL:
CREATE TABLE orders_part ( id SERIAL PRIMARY KEY, user_id INT, total DECIMAL(10, 2) ) PARTITION BY RANGE (total);
For applications that require more advanced scalability, PostgreSQL supports logical replication and streaming replication, allowing you to create read replicas to distribute read loads across multiple machines. However, unlike MongoDB’s sharding, PostgreSQL replication focuses more on scaling read operations rather than distributing write loads across multiple servers.
-
One of PostgreSQL’s key strengths is its support for parallel query execution. For large, complex queries, PostgreSQL can distribute the work across multiple CPU cores, dramatically speeding up query performance. This feature is particularly valuable for analytical workloads, where queries often need to process large volumes of data.
-
PostgreSQL's also has a built-in support for caching and partition pruning ensures that frequently accessed data can be retrieved quickly, reducing the load on the database during peak times.
While PostgreSQL’s horizontal scalability via partitioning and replication is powerful, it doesn’t come as naturally as MongoDB’s sharding. Setting up horizontal scaling in PostgreSQL requires more effort and is often a manual process that developers need to carefully design and implement.
5. Concurrency and Transaction Handling
MongoDB Concurrency
MongoDB’s approach to concurrency focuses on document-level atomicity. This means that operations affecting a single document are guaranteed to be atomic, either the entire operation succeeds, or it fails without leaving the document in an inconsistent state.
Prior to version 4.0, MongoDB did not support multi-document transactions, so atomicity was limited to operations on individual documents. However, with the release of MongoDB 4.0, full ACID transactions were introduced, allowing multiple documents across one or more collections to be updated as part of a single transaction.
MongoDB uses optimistic locking to handle concurrency. In an optimistic concurrency control model, it assumes that most database operations will not conflict, so instead of locking data preemptively, MongoDB only checks for conflicts when an update is attempted. This makes MongoDB highly efficient in write-heavy environments, as it minimizes locking overhead. In the event of a conflict, the system will retry the operation or abort the transaction.
Here’s an example of a simple multi-document transaction in MongoDB:
const session = db.startSession(); session.startTransaction(); db.orders.insert({ user_id: "001", total: 50 }, { session }); db.users.update({ _id: "001" }, { $set: { status: "active" } }, { session }); session.commitTransaction();
In this example, two separate operations, inserting an order and updating a user’s status — are bundled together within a transaction. If any part of the transaction fails, all changes are rolled back, maintaining the consistency of the data. MongoDB’s transactions are similar to traditional relational databases, making it easier for developers familiar with ACID transactions in SQL-based systems to work with MongoDB.
However, MongoDB’s concurrency model remains document-centric. Transactions in MongoDB are generally more lightweight compared to those in traditional relational databases, and while it supports transactions across multiple documents, MongoDB is often optimized for use cases where the data and operations are localized within a single document.
PostgreSQL Concurrency
PostgreSQL excels at managing concurrency through Multi-Version Concurrency Control (MVCC). This is a sophisticated technique that allows multiple transactions to interact with the database simultaneously without interfering with each other.
MVCC ensures that readers can see a consistent snapshot of the database even as other transactions are making changes. Essentially, each transaction sees a “version” of the database at the moment it started, unaffected by other concurrent transactions.
In PostgreSQL, every time a row is modified, a new version of that row is created, while older versions remain available for other transactions that need to read them. This ensures that readers never block writers and vice versa, which is a crucial feature for systems that require high performance in environments with multiple users or processes running concurrently.
PostgreSQL also supports a variety of isolation levels, which determine how isolated each transaction is from others. These levels include:

Here’s a simple example of a transaction in PostgreSQL:
BEGIN; INSERT INTO orders (user_id, total) VALUES (1, 50); UPDATE users SET status = 'active' WHERE id = 1; COMMIT;
In this transaction, PostgreSQL ensures that both the INSERT and UPDATE operations are executed as a single atomic unit. If an error occurs during the process, the transaction can be rolled back, preventing any partial changes from being applied to the database. With MVCC, other users or processes querying the users or orders tables will not see any inconsistent or partially updated data.
6. ACID Compliance and Data Integrity
With the introduction of multi-document ACID transactions supports atomic operations across multiple collections and databases, similar to relational databases. However, MongoDB is often used in systems that favor eventual consistency over strict ACID compliance, which works well for applications that can tolerate slight delays in consistency.
MongoDB ensures high availability through replica sets, where each set consists of a primary node and multiple secondary nodes. MongoDB Atlas automates replication and failover, ensuring that the system remains operational even during outages, with data replicated across multiple regions for disaster recovery.
PostgreSQL has been ACID-compliant since its inception, offering strong guarantees for atomicity, consistency, isolation, and durability across even the most complex transactions. This makes it ideal for applications where data integrity is critical, such as financial systems and ecommerce platforms.
PostgreSQL uses streaming and logical replication to ensure data availability. Streaming replication keeps standby replicas synchronized with the primary database, and tools like PostgreSQL Automatic Failover (PAF) ensure that, in case of a failure, a standby is promoted to primary seamlessly, maintaining system availability.
7. Partitioning and Sharding
MongoDB Sharding
MongoDB’s sharding system is a core feature that enables horizontal scaling by distributing data across multiple shards. A shard is essentially a subset of the data stored across different nodes or servers, and MongoDB uses a shard key to determine how to distribute documents.
The shard key is crucial in balancing the data load, as it defines how documents are assigned to different shards. MongoDB automatically manages data distribution and query routing through a mongos process, which acts as a query router that directs requests to the correct shard.
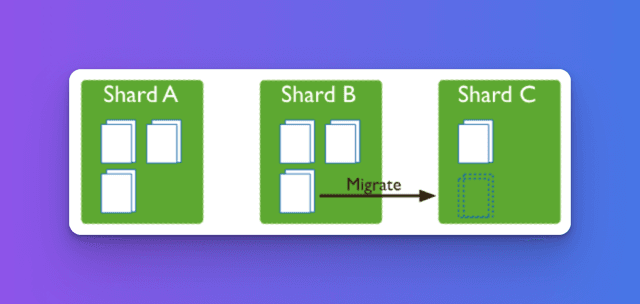
In a sharded MongoDB cluster, each shard can be part of a replica set, ensuring redundancy and high availability. MongoDB’s ability to perform live resharding—rebalancing data as the dataset grows—eliminates the need for downtime when scaling, which is particularly useful in real-time applications like ecommerce or social media platforms. The live resharding feature automatically redistributes data to avoid bottlenecks when certain shards become overburdened.
For example, sharding by a field like user_id in a large social media application can ensure that the user data is spread evenly across multiple servers:
sh.enableSharding("myDatabase") sh.shardCollection("myDatabase.users", { user_id: 1 })
This setup allows MongoDB to handle millions of users without performance degradation, as the system dynamically adjusts to the increasing workload.
PostgreSQL Partitioning
PostgreSQL supports declarative partitioning, allowing developers to split large tables into smaller, more manageable partitions based on specific criteria like range, list, or hash. Unlike MongoDB’s sharding, PostgreSQL’s partitioning operates within a single node, but it improves query performance and manageability by dividing large datasets.
For example, range partitioning can divide a table based on a date range:
CREATE TABLE orders ( id SERIAL PRIMARY KEY, order_date DATE, total DECIMAL(10, 2) ) PARTITION BY RANGE (order_date); CREATE TABLE orders_q1 PARTITION OF orders FOR VALUES FROM ('2024-01-01') TO ('2024-03-31');
This approach enables PostgreSQL to use partition pruning, meaning it only scans relevant partitions during queries, reducing the amount of data processed and improving performance. While it doesn’t have automatic rebalancing like MongoDB’s sharding, PostgreSQL’s partitioning can still handle large datasets effectively within a single node.
8. Extensibility and Customization
MongoDB Extensibility
MongoDB is highly flexible when it comes to defining document structures. Unlike relational databases that require strict schema definitions, MongoDB allows developers to store documents in a schema-less format, giving them the freedom to evolve the data model without altering the existing data structure. This is particularly useful in agile environments where data models can change frequently.
MongoDB also supports user-defined functions, written in JavaScript, which can be executed on the server to handle complex operations. For example, you can define a function to perform real-time calculations or transformations on your data:
// Define the JavaScript function var aggregateSalesByProduct = function () { var collection = db.getCollection("Sales") var pipeline = [ { $group: { _id: "$product", totalRevenue: { $sum: { $multiply: ["$quantity", "$price"] } }, }, }, { $sort: { totalRevenue: -1 } }, ] return collection.aggregate(pipeline).toArray() } // Save the function to MongoDB db.system.js.save({ _id: "aggregateSalesByProduct", value: aggregateSalesByProduct, }) // Test the function var result = db.eval("return aggregateSalesByProduct()") printjson(result)
MongoDB Atlas, its managed cloud service, takes extensibility further by offering App Services, including schema validation, triggers, and serverless functions. These services enable developers to build real-time applications with features like automated triggers that fire based on database changes, and schema validation ensures that even in a schema-less environment, some rules can still be enforced for data integrity.
PostgreSQL Extensibility
PostgreSQL’s extensibility is one of its strongest features, offering a wide range of tools for customizing database behavior. Developers can create custom data types, functions, and operators to extend the database’s functionality far beyond standard SQL operations. This level of customization makes PostgreSQL a preferred choice for applications requiring complex logic, such as scientific computing or GIS (geospatial information systems).
For instance, with the PostGIS extension, PostgreSQL adds support for geospatial queries, making it a powerful tool for applications that need to handle location-based data:
CREATE EXTENSION postgis; SELECT ST_AsText(ST_MakePoint(-71.064544, 42.28787));
In addition to PostGIS, PostgreSQL allows users to write stored procedures in several languages, such as PL/pgSQL, Python, Perl, or C, providing a high degree of flexibility when implementing custom logic. PostgreSQL’s extensible architecture also includes foreign data wrappers (FDW), which allow the database to interact with external data sources like other SQL databases, NoSQL databases, or APIs, effectively turning PostgreSQL into a multi-purpose data hub.
9. Security and Compliance
MongoDB security
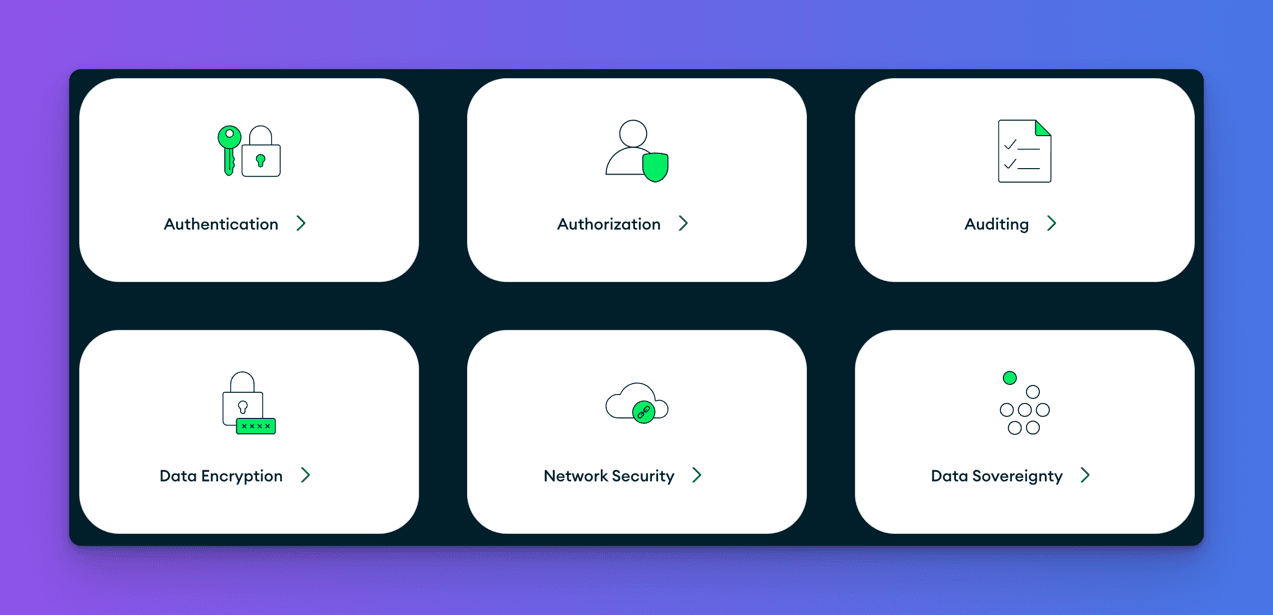
MongoDB provides robust, enterprise-grade security controls across various layers, ensuring data protection for cloud and on-premise environments.
- Authentication
MongoDB supports a wide range of authentication methods, including SCRAM, x.509 certificates, LDAP, and AWS-IAM for passwordless authentication. MongoDB Atlas, the managed service, extends this with multi-factor authentication (MFA) options such as OTP, hardware security keys (FIDO2), and biometrics, ensuring secure access to both the Atlas UI and databases. This multi-layered authentication ensures only authorized users can access the database.
- Authorization
MongoDB implements Role-Based Access Control (RBAC), allowing fine-grained control over user permissions. In MongoDB Atlas, roles are assigned at both the organization and project levels, defining access to cloud resources and MongoDB deployments. At the database level, roles govern specific permissions for actions on collections or databases. Identity federation can also be used to map roles with identity provider groups, streamlining access management in larger environments.
- Auditing
MongoDB offers detailed auditing capabilities, tracking actions such as create, read, update, and delete (CRUD) operations. The audit logs capture information on encryption key management, authentication processes, RBAC configurations, and critical operations like replication and sharding. These audit logs help prevent and detect unauthorized access, ensuring a secure environment with traceability of all operations.
- Data encryption
MongoDB ensures comprehensive data encryption for protecting sensitive information during its entire lifecycle:
- In-transit encryption secures data traveling across networks.
- At-rest encryption safeguards data stored on disk.
- In-use encryption protects data in memory and logs.
Key fields such as Personally Identifiable Information (PII) and Protected Health Information (PHI) can be encrypted automatically, offering a strong defense for sensitive data.
- Network Security
MongoDB Atlas enhances network security by deploying dedicated clusters in Virtual Private Clouds (VPCs) to isolate data from public internet access.
Private Endpoints allow one-way connections from cloud providers like AWS, Azure, or Google Cloud to Atlas clusters. VPC/VNet peering enables secure, direct communication between your MongoDB Atlas deployment and your application tier, while IP whitelisting restricts access to specific network segments.
- Data Sovereignty
MongoDB Atlas supports multi-region and multi-cloud deployments across 115+ regions on AWS, Google Cloud, and Azure. With zoned sharding, Atlas enables location-aware storage, ensuring data can be stored in specific geographic regions to meet data sovereignty and compliance requirements for globally distributed applications.
PostgreSQL Security
PostgreSQL offers robust, multi-layered security measures, ensuring data protection at various levels, making it ideal for industries like finance and healthcare.
- Database File Protection
PostgreSQL protects all files stored within the database, allowing access only to the *Postgres superuser account', preventing unauthorized access to raw data stored on disk.
- Connection Security
By default, PostgreSQL only allows local connections through a Unix socket.
Remote connections via TCP/IP must be explicitly enabled with the -i option. Client connections can be restricted by **IP address** and **username** using the pg_hba.conf` file, providing fine-grained control over who can access the database.
Example of IP-based connection restrictions:
host all all 192.168.1.0/24 md5
- User Authentication
PostgreSQL supports a wide range of authentication methods, including password-based authentication, LDAP, PAM, and certificate-based authentication. Each user is assigned a username and password, with access limited to databases they created unless explicitly granted permissions.
- Group and Role Management
PostgreSQL uses role-based access control (RBAC), allowing users to be grouped into roles for collective permission management. Permissions for accessing tables, views, and other objects can be granted or revoked at the group level, streamlining access control.
CREATE ROLE readonly; GRANT SELECT ON ALL TABLES IN SCHEMA public TO readonly;
- SSL Encryption and Client-Side Security
PostgreSQL supports SSL encryption to protect data transmitted between the client and server. It also supports row-level security (RLS), allowing administrators to define policies that control which rows specific users can access or modify.
Example of row-level security:
CREATE POLICY user_policy ON orders FOR SELECT USING (user_id = current_user);
- Compliance and Auditing
PostgreSQL offers strong logging and auditing capabilities, allowing for tracking of all database activity. Tools like the pgAudit extension provide detailed logging, ensuring compliance with regulations like GDPR, HIPAA, and PCI-DSS.
Conclusion
Both MongoDB and PostgreSQL are exceptional databases.
PostgreSQL is the go-to choice for apps requiring strong data integrity, complex transactions, and adherence to ACID principles. Its rich SQL-based ecosystem, advanced querying capabilities, and extensibility make it ideal for environments like financial systems, data analytics, and enterprise applications that need highly structured data with robust security controls.
MongoDB shines in scenarios where flexibility, scalability, and rapid development are crucial. Its document-oriented model, sharding capabilities, and support for handling unstructured or semi-structured data make it perfect for real-time applications, content management systems, and projects where the data model evolves frequently.
Related Developer Tools Comparison Articles
Check out these honest opinions: